

.png)
Understanding the trade-offs between model capability, speed, and cost
After working with production AI systems, we learned that the "best" model often depends on the specific task, latency requirements, and budget constraints. That's why Agno supports 40+ models across 20+ providers, from OpenAI and Anthropic to Groq, Ollama, and cloud providers like AWS Bedrock and Azure AI Foundry. With Agno’s modular syntax, testing different models is as simple as changing "openai:gpt-4o" to "groq:llama-3.3-70b-versatile". Experiment, measure, pick what works.
This guide walks through how to match models to tasks.
The impact of model mismatch
Consider a customer support agent built with GPT-4. After deployment:
- Monthly costs are higher than anticipated
- P95 latency averages multiple seconds
- Rate limits occur during peak traffic
The same workload, but with GPT-4o-mini for routine queries and Claude Sonnet for complex cases, can provide:
- Lower operational costs
- Faster response times for most queries
- Better resource utilization
The difference is the model selection strategy, not implementation.
Model selection criteria
Information current as of November 2025
Provider comparison
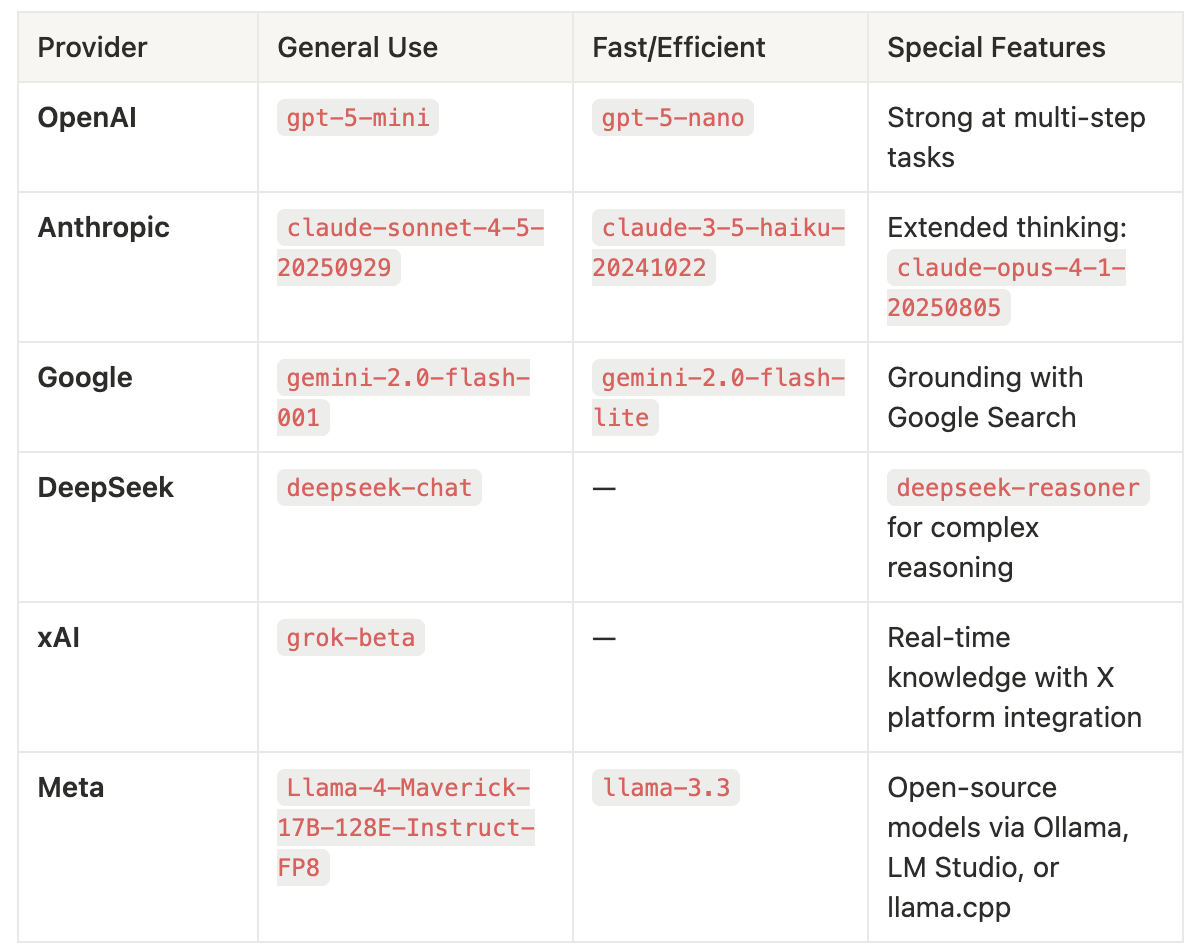
For complex reasoning tasks: Use OpenAI o1-pro or gpt-5-mini, DeepSeek-R1, or Google gemini-2.0-flash-thinking-exp-1219. Better yet, combine any response model with a reasoning model using Agno's reasoning_model parameter for best results.
Key:
- General Use: Good balance of speed, cost, and capability for most use-cases
- Fast/Efficient: Optimized for speed or small size
- Special Features: Unique advantages of each provider
Implementation patterns
Once you understand which models fit your needs, the next step is choosing the right architectural pattern. The key insight: you can use different models for different pieces of the execution loop, whether that's reasoning, response generation, parsing, or output formatting. Here are the most common patterns we've seen work in production.
Pattern 1: Single model
from agno.agent import Agent
agent = Agent(model="openai:gpt-4o", markdown=True)
agent.print_response("Share a 2 sentence horror story")
Model providers overview · Cookbook example
Pattern 2: Separate reasoning and response models
Reasoning models are "pre-trained to think before they answer" and "produce a long internal chain of thought before responding." Examples include OpenAI o1-pro and gpt-5-mini, Claude 4 in extended-thinking mode, Gemini 2.0 flash thinking, and DeepSeek-R1.
agent = Agent(
model="anthropic:claude-sonnet-4-5-20250929",
reasoning_model="groq:deepseek-r1-distill-llama-70b",
)
agent.print_response("9.11 and 9.9 -- which is bigger?", stream=True)
Why this pattern works:
This example uses a powerful reasoning model (DeepSeek-R1) to handle the complex thinking required to solve the problem, but then uses a faster, more cost-effective model (Claude Sonnet 4.5) to generate the final response. This gives you the best of both worlds: deep reasoning capability where you need it, but lower costs and faster response times for the actual output generation.
What if we wanted to use a Reasoning Model to reason but a different model to generate the response? Great news! Agno allows you to use a Reasoning Model and a different Response Model together. By using a separate model for reasoning and a different model for responding, we can have the best of both worlds.
Learn more: Reasoning models guide · Reasoning cookbook examples
Pattern 3: Local deployment
For development and experimentation, Agno supports local model execution via Ollama, LM Studio, llama.cpp, and VLLM:
from agno.agent import Agent
# Using Meta's Llama models through Ollama
agent = Agent(
model="ollama:llama3.3",
instructions="Process sensitive data",
)
When to use this pattern:
Local deployment is primarily for development and experimentation without burning through API costs. The real power comes from using local models during development, then seamlessly switching to cloud providers for production—or creating hybrid architectures where you can flex between local and cloud based on your needs.
Primary use case - Development:
- Local experimentation without API costs or rate limits
- Rapid prototyping and testing new approaches
- Offline development when internet is unavailable
Hybrid production approach:
- Develop locally with
ollama:llama3.3 - Deploy to production with
openai:gpt-4oby changing one line - Or run a hybrid: local models for certain tasks, cloud APIs for others
Edge cases - Pure local production:
- Air-gapped environments with no internet connectivity
- Strict regulatory compliance requiring on-premises data
Trade-off: You'll need adequate hardware (GPU recommended) and handle model updates/management yourself. Performance depends on your infrastructure, not provider optimizations.
For local usage with Ollama, install Ollama and run:
ollama pull llama3.1
Learn more: Ollama setup · Local deployment guide
Model switching considerations
When switching models during a conversation or across sessions, switching within the same provider is generally safer and more reliable.
Safe: Same provider
from agno.db.sqlite import SqliteDb
db = SqliteDb(db_file="agent_sessions.db")
# Initial model
agent = Agent(
model="openai:gpt-4o",
db=db,
add_history_to_context=True
)
# Switch within provider
agent = Agent(
model="openai:gpt-4o-mini",
db=db,
add_history_to_context=True
)
Risky: Cross-provider
Cross-provider switching is risky because message history formats between model providers are often not interchangeable, as some require message structures that others don't support.
agent1 = Agent(model="openai:gpt-4o", db=db)
agent2 = Agent(model="anthropic:claude-3-5-sonnet", db=db)
Learn more: Switching models FAQ
Model capabilities
All models on Agno support:
- Streaming responses
- Tool calling
- Structured outputs
- Async execution
Multimodal support varies by provider. Some models support image input, audio input, audio responses, video input, and file upload—check the compatibility matrix for details.
Summary
Model selection should match task requirements. Use:
- OpenAI GPT-4o or Claude Sonnet 4 for general-purpose tasks
- Reasoning models (o1, DeepSeek-R1, Claude extended-thinking) for complex problem-solving
- Local models for development/experimentation (seamlessly switch to cloud for production)
- Model combinations (reasoning + response) for optimal cost-performance
Agno supports 20+ providers with patterns like separate reasoning and response models to optimize for different use cases. Agno agents instantiate 529× faster than LangGraph with a 24× lower memory footprint, and apply similar optimization thinking to model selection.
Resources:
- Agno Documentation - Complete guides and API reference
- Model Providers Overview - All 20+ integrations
- GitHub Repository - Source code and examples
- Cookbook Examples - Working implementations
- Model-specific Examples - Provider guides