

.png)
How does context engineering help you create AI agents that are faster, more efficient, and better at working together in multi-agent systems?
During agent development, you find your agent doesn’t want to call the right tools or give the right responses consistently. Maybe your team of agents ran searches in parallel instead of collaborating. Your token costs hit production scale, and suddenly, your CFO started asking questions.
Why do some AI agents perform flawlessly in production while others fall apart under pressure?
The difference often comes down to one thing: context engineering.
Context engineering is the process of designing and optimizing the information an AI agent sends to and receives from a large language model (LLM). In other words, it’s how you control what the model knows, remembers, and pays attention to. At its core, it comes down to one question: "Which set of information is most likely to achieve the desired outcome?"
In this blog, we’ll explore how to apply practical context engineering techniques using Agno to build smarter, faster, and more collaborative AI systems. You’ll learn how to:
- Design system messages that actually work
- Decide what context to include (and what to skip)
- Implement context caching to lower latency and cost
- Use few-shot learning to shape agent behavior
- Coordinate multi-agent teams for seamless collaboration
System Messages: Get This Right First
What are system messages in AI agents, and why are they so critical for context engineering?
The base of every LLM interaction is the system message, sometimes referred to as the system prompt. If you get this wrong, nothing else matters.
So, what does an AI agent system message do? A system message is a set of pre-written instructions and context that define an AI agent’s purpose, tone, limitations, and output format. It essentially serves as the agent’s core “DNA” for a given interaction.
Agno constructs the system message from multiple components, with three of the most useful being description, instructions, and expected output:
Description sets the agent's identity and is added to the start of the system message. It defines the agent’s purpose or domain. You'll want to be specific here. "You are a helpful assistant" gives little direction. This type of description offers little guidance on what the agent should focus on and what it should avoid. "You are a famous short story writer asked to write for a magazine" gives the agent clear domain expertise and well-defined constraints. It's a much better AI agent description, as a well-defined identity immediately improves output quality. When it comes to the description component of system messages, identity alone isn't enough; you need precision.
Instructions are added to the system message inside <instructions> tags and should be written as structured lists. The structure matters. We've found that discrete, actionable steps work better than prose paragraphs. Think checklist, not essay. Each instruction should stand on its own and be independently understandable. This is where you translate "what the agent should be" into "how the agent should act."
Expected output prevents format chaos. Without it, you might get a paragraph for one request, bullet points for the next, and inconsistent or incomplete answers in between. Being explicit about structure keeps outputs consistent and clear. For example, "Provide a three-section report: Executive Summary, Detailed Analysis, Risk Assessment" is specific enough to guide the agent but flexible enough to let it adapt to different queries.
How long should a system message be? There is no real rule, so you’ll likely need to experiment with the ideal system message length until you find what works best. ‘Not too long and not too short’ is a good rule of thumb. If the system message is too short, the AI won’t have enough context to know what to do and how to operate. If the system message is too long, the AI has too many things to keep in mind.
Here's what this looks like in practice:
agent = Agent(
description="You are a famous short story writer asked to write for a magazine",
instructions=[
"Create 5-sentence stories",
"Always make the setting of the stories in the modern era",
"Include a twist ending that subverts reader expectations"
],
expected_output="Two compelling sentences with clear setup and shocking twist.",
debug_mode=True
)
agent.print_response("Create a funny story about a cat and a giraffe")
Notice debug_mode=True.
This is useful during development because it shows you the actual compiled system message being sent to the model. You'll catch issues you didn't know existed.
View a more complete example in our research agent cookbook. For a complete reference of all system message parameters and context manipulation options, see the Agent Context docs and Team Context docs.
Context Features: The Selective Addition Problem
How can you optimize AI agent context without wasting tokens?
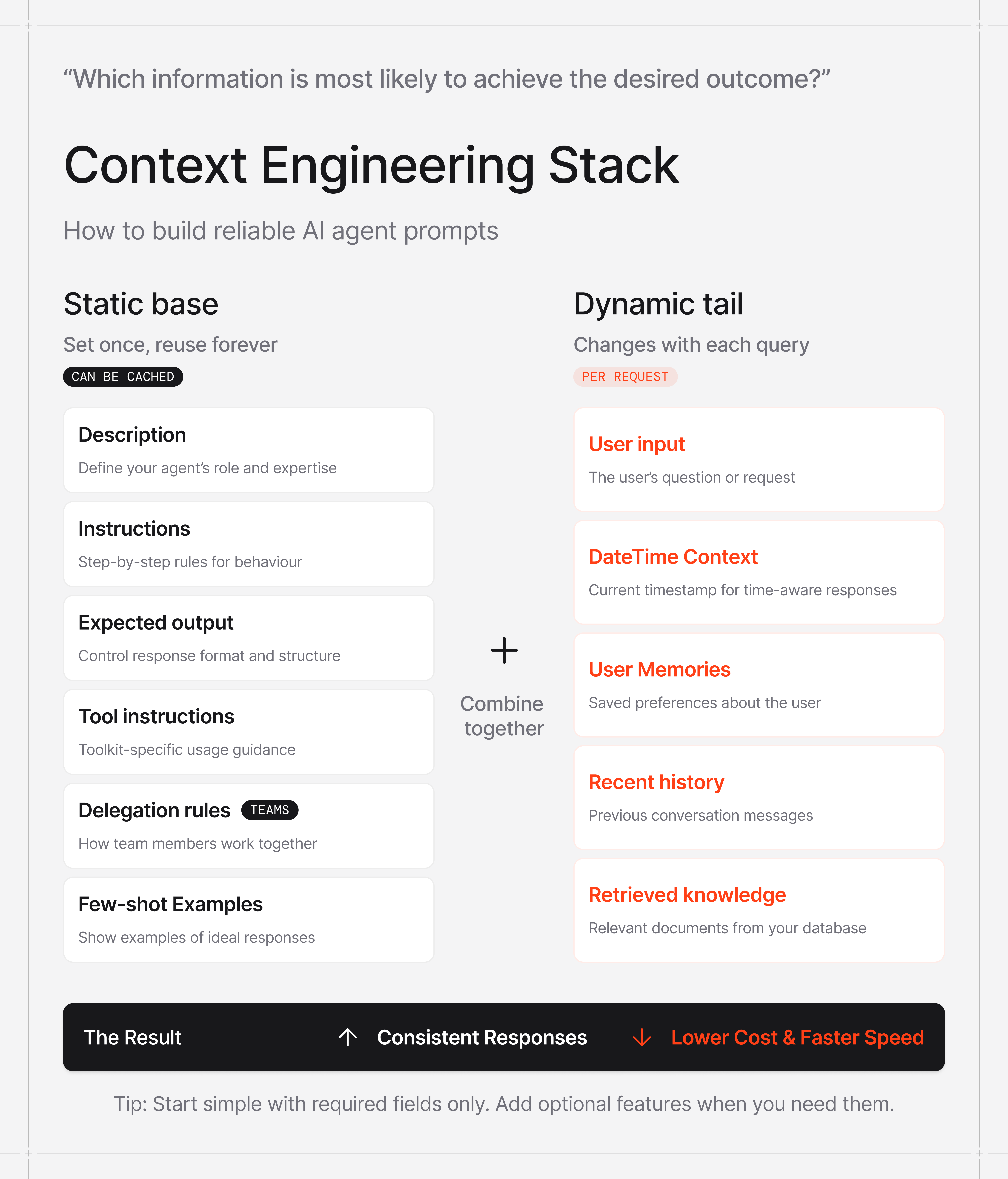
Building with language models isn't just about finding the right words and phrases for your prompts. Increasingly, it’s about answering a deeper question: what configuration of context is most likely to produce the desired behavior?
In context engineering, context refers to the set of tokens an LLM sees and reasons over during generation. The challenge lies in optimizing those tokens, balancing signal and noise within the model’s finite attention window to consistently achieve the outcome you want.
Effective context engineering means thinking holistically about the model’s state: what information it has access to, how that shapes its reasoning, and what behaviors it’s likely to produce. Since every token counts, the goal is to find the smallest, highest-signal set of tokens that maximizes performance.
This is easier said than done. In this section, we’ll look at how this principle plays out in practice, specifically how Agno’s context parameters help you fine-tune what information your agent truly needs.
Agno gives you various parameters to enrich context: add_datetime_to_context, add_memories_to_context, add_history_to_context, add_knowledge_to_context, and more. Your instinct might be to turn everything on. More context means better results, right?
Not quite. Each line in your system message costs tokens and adds to your model’s context, potentially degrading model accuracy.
Here is a typical pattern: A customer support agent for a travel agency, with all the above context features enabled, adds all user preferences (memories), knowledge related to the user’s request, history of previous conversations, etc., into the context. Every request now consumes more than 200k tokens before an answer is even provided! Changing the agent configuration to only add instructions and perhaps allowing the agent to retrieve relevant user memories and knowledge using tools instead decreases token usage dramatically.
The pattern that works: be selective based on what the agent actually needs to know.
For example, enabling chat history for an agent can be really powerful, as it helps them remember the context of the conversation with the user more effectively. However, granting the agent unlimited access to history will definitely cause token usage to exceed the limits of your model.
View a full example of an agent with chat history enabled in our agent session cookbook.
agent = Agent(
add_history_to_context=True,
num_history_runs=3,
)
The num_history_runs=3 parameter limits context to just the previous three conversation turns. This balances continuity with efficiency. The agent can reference recent context without drowning in old messages.
We made these features opt-in by design. It forces you to think about what each agent actually needs rather than defaulting to "give it everything."
Once you’ve mastered the art of selecting what to include in context, the next challenge is teaching the model how to behave within that context. You don’t always need to spell everything out through rules or instructions; sometimes the best way to shape behavior is through demonstration. This is where few-shot learning comes in.
Few-Shot Learning: Show, Don't Just Tell
How can you teach AI agents tone, structure, and reasoning through practical examples?
Instead of writing instructions that describe ideal behavior, aka telling the agent what to do, you can show the agent examples of ideal behavior. This is called few-shot prompting, and it can be very effective.
You can add examples using the additional_input parameter. The messages get inserted into the context as if they were part of the conversation history. See a full example of how to use additional_input with an Agent
to teach proper response patterns through few-shot learning.
support_examples = [
Message(role="user", content="I forgot my password and can't log in"),
Message(role="assistant", content="""
I'll help you reset your password right away.
**Steps to Reset Your Password:**
1. Go to the login page and click "Forgot Password"
2. Enter your email address
3. Check your email for the reset link
4. Follow the link to create a new password
If you don't receive the email within 5 minutes, check your spam folder.
""".strip()),
Message(role="user", content="I've been charged twice for the same order and I'm frustrated!"),
Message(role="assistant", content="""
I sincerely apologize for the billing error and the frustration this has caused you.
**Immediate Action Plan:**
1. I'll investigate your account to confirm the duplicate charge
2. Process a full refund for the duplicate transaction
3. Provide you with a confirmation number once processed
The refund typically takes 3-5 business days to appear on your statement.
""".strip()),
]
# Use these examples to train the agent
agent = Agent(
additional_input=support_examples,
instructions=[
"You are an expert customer support specialist.",
"Always be empathetic, professional, and solution-oriented.",
],
)
This teaches tone, structure, and depth through demonstration. The agent learns not just what to do but how to do it. You'll see much more consistent responses, especially for customer-facing agents where voice matters.
Few-shot examples can make a single agent remarkably capable—able to reason, respond, and adapt with nuance. But as soon as you introduce multiple agents, a new challenge appears: coordination. Teaching one agent how to behave is one thing; ensuring several agents work together smoothly toward a shared goal is another.
Multi-Agent Teams: Where Coordination Matters
How does context engineering enable team leader agents to coordinate members, manage roles, and maintain consistent performance across multi-agent systems?
Single agents are straightforward. Multi-agent teams introduce a new layer of complexity.
The challenge: in a multi-agent setup, a team leader agent orchestrates the workflow. The leader’s role is to understand each member’s capabilities, delegate tasks effectively, and integrate their outputs into a cohesive response. Without this understanding, the leader can’t match tasks to the right agents or ensure consistent results across the team.
Here's a complete working example of a research team in action: Agent Team Example.
Agno handles this by automatically injecting member information into the team leader's system message. This includes member IDs, roles, and critically, the tools each member has access to:
<team_members>
- Agent 1:
- ID: web-researcher
- Name: Web Researcher
- Role: You are a web researcher who can find information on the web.
- Member tools:
- duckduckgo_search
- duckduckgo_news
- Agent 2:
- ID: hacker-news-researcher
- Name: HackerNews Researcher
- Role: You are a HackerNews researcher who can find information on HackerNews::
- get_top_hackernews_stories
- get_user_details
</team_members>
The system message also includes delegation guidelines in <how_to_respond> tags. These explain how to analyze member capabilities, what information to include when delegating, and when to re-delegate if results aren't sufficient.
Member information alone isn't always enough. You need to encode behavioral patterns directly into the team's instructions, like in this multi-agent team cookbook.
agent_team = Team(
members=[web_agent, hackernews_agent],
instructions=[
"You are a team of researchers that can find information on the web and Hacker News.",
"After finding information about the topic, compile a joint report."
]
)
That second instruction matters. "After finding information about the topic, compile a joint report," tells the leader how to process and synthesize member outputs before responding.
Advanced Context Patterns
How can advanced context engineering give AI agents autonomy through memory, retrieval-augmented generation, and tool-specific instructions?
Once agents can collaborate effectively as a team, the next step is giving them the ability to manage knowledge and adapt over time. This is where advanced context patterns come into play. These features—like agentic memory, retrieval-augmented generation (RAG), and tool-specific instructions—extend what agents can do beyond static prompts. They enable agents to remember user preferences, search information dynamically, and use tools more intelligently, all while maintaining efficiency and control over context size.
Agentic Memory lets agents manage their own memories. Set enable_agentic_memory=True, and the system message will include instructions about using the update_user_memory tool.
During a conversation, if the agent notices information worth remembering (like "User prefers quarterly reports over monthly"), it can save this as a memory. The next interaction automatically includes this preference in context. The agent curates its own memory database as it learns about the user. See a full example in this persistent memory cookbook.
Agentic RAG lets agents search your knowledge base themselves. Set search_knowledge=True , and the agent gets a search_knowledge_base tool. Instead of automatically injecting references into the context, the agent decides when to search and what to search for.
This is powerful because the agent only retrieves knowledge when it's relevant. A user asking "What's the weather?" won't trigger unnecessary knowledge searches. But "What did the Q4 report say about revenue?" prompts the agent to search your documents for the answer. The agent controls its own RAG pipeline. See a full example in this Agentic RAG cookbook.
Tool Instructions can be added directly to your system message. If you're using a Toolkit on your agent, you can add instructions to the system message using the instructions parameter on the Toolkit with add_instructions=True. For example, consider the GitHub toolkit, instructions can clarify when to the agent should use send_message versus send_message_thread. This makes tools more discoverable and improves usage patterns. (See Toolkit docs)
As agents gain the ability to remember, reason, and retrieve information on their own, the amount of context they carry inevitably grows. Every new feature—memory, knowledge search, tool instructions—adds valuable capability but also increases token load. To keep performance high and costs manageable, you need a strategy for reusing what doesn’t change between requests. That’s where context caching comes in.
Context Caching: The Performance Pattern
How does context caching reduce token costs and improve AI agent performance at scale?
As agents become more sophisticated, the length of context becomes a significant concern. Rich system messages can hit 100k+ tokens before any user input. At production scale, this matters.
Most model providers support prompt caching. The key is to structure your system message so that static content comes first and dynamic content comes last.
Agno's context construction follows this pattern by default:
- Agent/team description (static)
- Member information and delegation rules (static)
- Core instructions (static)
- User memories (dynamic)
- Retrieved knowledge (dynamic)
- etc.
This ordering means the bulk of the system message gets cached and reused across requests. For high-volume production systems, this substantially reduces both cost and latency. The static portion caches once, then reuses it for every request. Only the dynamic tail changes per query.
For multi-agent teams, member information and delegation guidelines are typically static, perfect candidates for caching.
One caveat is that not all model providers enable caching automatically. See our docs for more information.
Take a look at how some of the major model providers do prompt caching:
Getting Context Right
How Can Context Engineering Make or Break Your AI Agents?
The difference between an AI agent that shines in demos and one that scales reliably in production isn’t just about choosing the right model—it’s about context engineering. Getting the context right determines how well your agents perform under real-world conditions. The patterns we’ve covered—system messages, selective context, few-shot examples, and multi-agent coordination—tackle real production challenges such as token costs, inconsistent behavior, and wasted team effort.
For a complete list of context parameters and advanced options, see the Agent Context docs and Team Context docs.
Acknowledgements
This post was written by Dirk Brand, Agno’s Head of Engineering, and Nancy Chauhan, Senior Developer Experience Engineer.